
🧰 The Builder's Issue: Qwen3.5 Small, NotebookLM Styles, and CUDA at Scale
March 4, 2026


It’s Wednesday, March 4th: Open source is winning this week. Alibaba just shrunk a 120B-class reasoning model down to 9B parameters, NotebookLM is making your research actually look good, and a new agentic RL system is writing CUDA kernels faster than most GPU engineers ever could.


Head over to our Events Portal to get the latest on upcoming AI Collective events near you. Search by city, date, or event format, and join thousands of builders at events across 100+ chapters on every continent (except Antarctica, for now).
🌁 Based in SF? Check out SF IRL, MLOps SF, GenerativeAISF, or Cerebral Valley’s spreadsheet for more!

In Today’s Top Tools, we spotlight some of the most innovative, creative AI apps that we recommend adding to your stack.
1️⃣ Alibaba releases open-source Qwen3.5 Small series where 9B beats 120B-class models on reasoning benchmarks

Alibaba released the Qwen3.5 Small Series, four models from 0.8B to 9B parameters that bring “big model” reasoning into a footprint you can actually ship. The 9B flagship outperforms OpenAI’s 120B gpt-oss on multilingual knowledge and graduate-level reasoning benchmarks, while still running on a single high-end GPU or even strong consumer hardware. You can deploy them locally across everything from laptops to edge devices without giving up modern MoE and linear-attention tricks.
Model lineup
Each model is tuned for a specific hardware tier and use case.
0.8B & 2B: Edge-focused, optimized for phones, wearables, and low-power sensors while still handling text and lightweight multimodal inputs.
4B: Native multimodal model with a 262,144-token context window, positioned as a compact “agent base” that can see long documents, images, and even video.
9B: The flagship reasoning model that rivals or beats 120B-class dense models while being roughly 13x smaller in active parameters.
Architecture
Instead of distilling from a huge dense model, Qwen3.5 Small uses a hybrid architecture combining Gated Delta Networks (a linear attention variant) with sparse Mixture-of-Experts.
Linear/hybrid attention slashes memory and compute, making million-token contexts practical on commodity hardware.
Sparse MoE only activates a small subset of experts per token, so you get “virtual” large-model capacity without paying full inference cost.
Early multimodal fusion trains text and vision together from scratch, instead of bolting on encoders after the fact.
How to run it
You can pull the models and wire them into existing open-source stacks in a few minutes.
Available on Hugging Face and Alibaba’s ModelScope hub for direct download.
Works with Ollama, llama.cpp, and Hugging Face Transformers for local or server deployments.
Base checkpoints are released for fine-tuning, evaluation, and research—no closed weights or gated APIs required.
2️⃣ Google NotebookLM rolls out Custom Styles for Infographics

NotebookLM now lets you turn dense notes into polished infographics with a single click and a style that actually feels on-brand. The new Custom Styles feature ships with 10 preset looks and the ability to define your own, so you can move from “raw research dump” to shareable visual without opening a design tool.
What’s new
You can pick from presets like editorial, clay, brick, and fan-favorite kawaii, or dial in a fully custom aesthetic.
Switch style inside the infographic editor by clicking the pencil icon, then adjust language, orientation, and detail level.
Apply styles to long-form source material—reports, study notes, research docs—and let NotebookLM handle layout and hierarchy.
Why it matters
For anyone doing tutorials, explainers, or internal updates, this removes the design bottleneck.
One-click generation means you can iterate on content structure instead of fiddling with fonts and spacing.
Custom styles make it easy to keep visuals consistent with your brand, course, or social feed.
Where to use it
The feature is live in the Studio panel of NotebookLM.
Upload your material, generate an infographic, then tweak style and detail until it fits your audience.
Ideal for learning summaries, knowledge sharing, and slide-ready diagrams.
3️⃣ CUDA Agent – Large-scale agentic RL for high-performance CUDA kernel generation
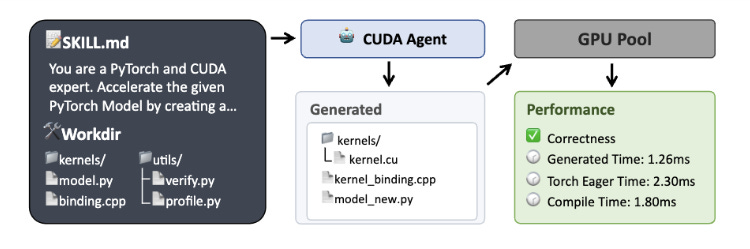
CUDA Agent is a large-scale agentic RL system that teaches models to generate and optimize CUDA kernels like a seasoned GPU engineer. It combines a scalable task synthesis pipeline, a skill-augmented CUDA development environment, and long-horizon reinforcement learning to beat both torch.compile and strong proprietary models on KernelBench.
What it does
Instead of treating code generation as a one-shot problem, CUDA Agent runs a full ReAct-style agent loop over a GPU sandbox.
Synthesizes thousands of fused operator tasks from real PyTorch and Transformers workloads, then filters them with execution checks.
Lets the agent write kernels, compile, profile, and iteratively optimize while receiving correctness and performance rewards.
Uses anti-reward-hacking safeguards so the model can’t “cheat” by returning constants or falling back to high-level APIs.
Training pipeline
The team stabilizes long-context RL with a staged training process.
Single-turn PPO warm-up improves baseline CUDA generation before entering multi-turn loops.
Rejection Fine-Tuning filters out bad trajectories and tool-call patterns to keep the policy from collapsing.
A pretrained critic provides reliable value estimates across sequences up to 128k tokens and 150–200 interaction turns.
Why it matters for builders
On KernelBench, CUDA Agent reaches a 98.8% pass rate and delivers a 2.11x geometric mean speedup over torch.compile overall, with even larger gains on harder tasks.
Overall: 96.8% of tasks run faster than torch.compile and 2.60x speedup vs eager mode.
Level-3 (hard) tasks: 90% faster-than-compile rate and 1.52x speedup vs compile, widening the gap with top proprietary models.
For teams pushing custom kernels or performance-sensitive ops, this points to a future where RL-trained agents sit in your GPU toolchain, continuously generating and tuning kernels instead of relying only on compiler heuristics.

Here are a few standout opportunities from companies building at the edge of AI. Each role is selected for impact, growth potential, and relevance to our community.
Senior Product Engineer, Agentic AI, Hive, Canada / Remote ($111K - $140K CAD): “Join Hive’s Agentic AI Pod to build and ship experimental conversational interfaces and autonomous marketing agents that let 1,500+ iconic events and festivals get real, measurable work done through natural language and intelligent automation.”
Founding Engineer (Machine Learning), MorphoAI, London / New York / San Francisco (£50K - £110K GBP): “Work directly with the CTO to build and deploy AI-powered invention tools for robotics and complex cyber-physical systems, applying generative AI, physical simulation, numerical optimization, and PyTorch to products that shorten time-to-market for robots and machines.”
Senior Software Engineer – AI Engineering, Sixtyfour, San Francisco ($150K - $250K - 0.10% - 0.30%): “Design and ship production-grade AI agents that reason over complex human and organizational data — building agentic systems with tool calling, multi-step reasoning loops, and web intelligence pipelines that solve high-stakes identity verification and entity resolution problems for enterprise customers.”
Software Engineer, Idler, San Francisco ($100K - $150K - 0.05% - 0.25%): “Build agentic tooling and UI systems for Idler’s reinforcement learning environments — real-world coding scenarios used to train frontier AI models to code like 0.01% engineers — at a company that has already closed a multimillion-dollar contract with a leading foundation lab.”
📝 Community Notes
🌁 HumanX 2026 — April 6-9

HumanX 2026 (April 6–9) brings a concentrated slice of the AI ecosystem into one building in San Francisco. The speaker and attendee list spans Fei-Fei Li, Andrew Ng, Ray Kurzweil, founders from Databricks, Replit, Pika, Cohere, ElevenLabs, Cerebras, and CEOs from AWS, Snowflake, Zoom, along with partners from a16z, Greylock, Kleiner Perkins, General Catalyst, and hundreds more.
Last year, founders walked away with Series A rounds and enterprise partnerships that started as hallway conversations or demo-booth follow-ups. This year, The AI Collective will be on-site running 18+ programs and hosting a major exhibit on the floor, giving our community a clear home base inside the conference. With roughly 70% of attendees at VP-level and above, the value is less about volume and more about the density of decision-makers across industry, startups, and capital.
If you’re actively building or leading in applied AI, this is one of the rare weeks where your users, partners, and future investors are literally in the same building.
Our Premier Partner: Roam

Roam is the virtual workspace our team relies on to stay connected across time zones. It makes collaboration feel natural with shared spaces, private rooms, and built-in AI tools.
Roam’s focus on human-centered collaboration is why they’re our Premier Partner, supporting our mission to connect the builders and leaders shaping the future of AI.
Experience Roam yourself with a free 14-day trial!
➡️ Before You Go
Partner With Us
Launching a new product or hosting an event? Put your work in front of our global audience of builders, founders, and operators — we feature select products and announcements that offer real value to our readers.
👉 To be featured or sponsor a placement, reach out to our team.
The AI Collective is a community of volunteers, made for volunteers. All proceeds directly fund future initiatives that benefit this community.
Stay Connected
💬 Slack: AI Collective
🧑💼 LinkedIn: The AI Collective
𝕏 Twitter / X: @_AI_Collective
Get Involved
About the Authors
About Joy Dong
Joy is a news editor, writer, and entrepreneur at the forefront of the emerging tech landscape. A former educator turned media strategist, she currently anchors TEA, where she demystifies complex systems to make AI and blockchain accessible for all. Joy is on a mission to explore how decentralized technology and artificial intelligence can be leveraged to build a more innovative and transparent future.
About Noah Frank
Noah is a researcher, innovation strategist, and ex-founder thinking and writing about the future of AI. His work and body of research focus on aligning governance strategies to anticipate transformative change before it happens.
The Qwen 3.5 Small models are the ones I'm most excited about honestly. The flagship gets all the attention but a 4B dense model that does multimodal natively and runs on any laptop from the last five years is a bigger deal for most people. Wrote up the full MoE vs dense breakdown and what the benchmarks actually mean when you strip away the marketing: https://reading.sh/your-laptop-is-an-ai-server-now-370bad238461